Минцифры предложило перечень приоритетных направлений для развития технологий искусственного интеллекта, среди них — госуслуги, территориальное развитие, медицинская диагностика, анализ спутниковых снимков и наблюдение за погодой. Кроме того, Минэкономразвития намерено обязать бизнес использовать ИИ, если он хочет получить субсидии. По мнению экспертов, областей и сценариев применения искусственного интеллекта намного больше указанных, при этом важно, внедряя такие технологии, обеспечивать прозрачность систем ИИ
Искусственный интеллект уже второй год подряд становится самой обсуждаемой технологией во всем мире. К ней приковано внимание общества, бизнеса и государства. Он одновременно восхищает и пугает людей, а инвестиции в ИИ исчисляются десятками миллиардов долларов. О том, что же такое современный искусственный интеллект, в интервью «Российской газете» рассказал генеральный директор Института искусственного интеллекта AIRI, доктор физико-математических наук, профессор РАН и Сколтеха, Иван Оселедец.

Почему многие люди боятся ИИ, откуда взялся этот страх?
Отчасти это влияние поп-культуры, таких фильмов, как «Терминатор» и других ярких художественных произведений. У меня и моих коллег перед матричными умножениями – так, собственно, и работает нейросеть – страха нет, скорее интересует вопрос почему же она все-таки работает. Действительно интересно все это осознать, понять какими средствами и каким языком описать.
Искусственный интеллект на основе нейросетевых моделей пережил первый пик интереса в 2016 году после матча нейросети AlphaGo и первого игрока мирового рейтинга в игру Го, Ли Седоля. Но тогда кроме специалистов на победу AlphaGo никто не обратил внимания. Что изменилось за 6 лет, почему с 2022 года ИИ постоянно находится на пике общественного интереса?
Ответ на этот вопрос очень прост – ChatGPT. Это действительно прорывная история в первую очередь за счет колоссально выросшего качества общения ИИ с человеком. На самом деле искусственный интеллект используется очень давно, например, в камерах, которые распознают лица с потрясающей точностью или в интернет-торговле. ИИ уже с нами, он уже здесь. Но такой формат взаимодействия с ИИ не производил такого впечатления на людей, как возможность лично пообщаться с ИИ.
Главная идея ChatGPT заключалась в том, чтобы не обучаться на большом количестве произвольных текстов из интернета, а добавить в процесс обучения нейросетевой модели обратную связь от человека. То, что называется RLHF (reinforcement learning human feedback) Оказалось, что качественные данные и обратная связь от человека приводят к существенному скачку в качестве модели.
То есть локомотивом всего хайпа вокруг ИИ стал один яркий продукт?
Да, локомотивом действительно стала новая методика обучения и конкретно ChatGPT, который Open AI выложили в публичный доступ. Как только люди стали пользоваться ChatGPT, это привело, к колоссальному взрыву интереса. Сейчас у многих людей эта штука открыта в ежедневном режиме, каждый для себя (по крайней мере я могу про себя и коллег говорить) находят там широкий спектр применений. Интересно, что хотя это очень мощная технология, на самом деле ее не очень сложно повторить. В последние несколько месяцев появилось нескольких открытых OpenSource моделей чуть меньшего размера. Так что это только начало. В ближайшее там время нас ждет очень много интересного.

Как вы относитесь к письму организации Future of Life, которое подписали Илон Маск, сооснователь Apple Стив Возняк и другие известные персоны, относительно приостановки разработок в области ИИ ввиду его потенциальной опасности для людей?
Я, конечно, не поддерживаю идею что надо что-то остановить, прекратить, тем более что некоторые люди, которые подписывали это письмо, например Илон Маск, потом вкладывали деньги в свою компанию по разработке ИИ. Есть и такие экзальтированные исследователи ИИ, как Элиезер Юдковский, который дошел до того, что фактически призывает бомбить дата-центры, где обучают нейросетевые модели.
Все это выглядит очень странно. Действительно, сейчас технологии машинного обучения хорошо работает там, где цена ошибки не высока. Никто не может дать гарантии стопроцентно безошибочной работы ИИ, но мы и для человека не можем дать такой гарантии, а ошибки человека, которые случаются, устраняем путем внесения изменений в регламенты, обучение, в подготовку. Такие же процедуры работают и для искусственного интеллекта. Если, например, мы поставим нейросетевую модель управлять транспортом, и она перестанет корректно работать, надо будет разобраться, почему это произошло и решить проблему так же, как и в случае с обучением человека.
Мне кажется, сейчас надо максимально вкладываться в развитие ИИ. Естественно, если в какой-то момент мы упремся в технологический или иной барьер, тогда и надо будет думать, что делать дальше. Однако, многие задачи, которые раньше считались для ИИ сложно решаемыми, современные большие языковые модели (LLM) решают легко. Это замечательно, значит, надо учиться этими моделями пользоваться, надо учиться с ними взаимодействовать. То, что происходит сейчас с ИИ сравнимо с предыдущими технологическими революциями, но я опять же не вижу в этом ничего страшного или критичного. В мире, будем честны, гораздо больше более серьезных проблем – голод, болезни, стихийные бедствия – чем гипотетический захват власти над миром каким-то супермозгом.
Что вы думаете относительно социальных последствий массового внедрения ИИ? Насколько оправданы опасения его противников, что ИИ лишит их работы, профессии?
Если ИИ сможет автоматизировать рутинные процессы в этом нет ничего плохого. Люди смогут сфокусироваться на более интересных и творческих вещах. Но пока не все так просто. Возьмем, программирование и написание кода. Уже было несколько случаев, когда нейросеть за 3 минуты писала код. Очень правдоподобно писала, но с такими хитрыми ошибками, что человек потом 3 часа искал этот несчастный баг. Если же учесть, что программистов сейчас не хватает во всем мире, рынок труда перегрет, то в том, что самый простой код будет писать ИИ нет ничего плохого.
Как далеко мы сейчас находимся от того, что называют «общим искусственным интеллектом»? Он в принципе возможен?
На эту тему очень много спекуляций, но если бы год назад я сказал «вряд ли» или «надо подождать», то с появлением ChatGPT многое изменилось. Почему бы те вещи, которые он сейчас делает, не рассматривать как проявление общего искусственного интеллекта, который отвечает на многие вопросы лучше среднестатистического человека, решает разнообразные задачи, выполняет роль помощника. Что тут не соответствует понятию «общего искусственного интеллекта». Кейсы с использованием современного ИИ – это очень многозадачные истории и даже в некоторых случаях достаточно креативные. В этом смысле мы подошли очень близко к общему ИИ. Он неожиданно для многих появился в форме чат-бота, который обрастает различными модальностями, то есть, уже работает не только с текстом, но и с изображениями и видео. Можно считать, что мы уже живем в эпоху более или менее «общего ИИ». Человечество в каком-то смысле пересекло эту условную черту. Конечно, можно спорить относительно определения общего ИИ, но факт остается фактом, поведение современных больших языковых моделей принципиально отличается от того, что мы видели раньше и их действительно можно назвать прототипами общего ИИ.
Каково на ваш взгляд сейчас место России в мировой ИИ-индустрии в науке о данных?
В области Data Science (науки о данных), думаю, мы входим в Топ 15–20 стран. Это достаточно легко измерить количеством публикаций на конференциях. Хотелось бы, конечно, больше так как в этом нет ничего сложного. Data Science наука достаточно своеобразная и нетипичная для нашей академической традиции, так как она не подразумевает каких-то глубоких фундаментальных исследований, а представляет собой набор быстрых и успешных рецептов, которые люди придумывают и используют.
Если говорить с точки зрения развития прикладных технологий у нас все очень неплохо. Я обычно привожу как пример обработку медицинских изображений, где по многим показателям Москва находится в мировых лидерах. Тут опять все сводится к тому, что нужно правильно собрать данные и обучить модели, но тем не менее, такого внедрения этой технологии, как в Москве, нигде в мире практически нет.
Сегодня каждая уважающая себя российская IT-компания или банк имеет у себя отдел, занимающийся машинным обучением. В «Сколтехе» есть свои научные группы, они работают, появляются новые, но я думаю, что нужно раза в четыре-пять больше научных групп, работающих в области ML (машинного обучения). В целом же ситуация с искусственным интеллектом в стране неплохая, туда вкладываются деньги, есть проекты, есть поддержка.
Обучение больших нейросетевых моделей требует значительных вычислительных ресурсов. Насколько реально создавать суперкомпьютеры в текущих условиях в России? Что для этого нужно?
Санкционная история просто повышает стоимость вычислительных ресурсов и их доступность. Но при этом программное обеспечение, которым все пользуются, не очень эффективно. Сейчас вычислительный кластер достигает при стандартной методике обучения не более 50 % от своей максимальной производительности. Если же, условно, приблизиться к 100 %, можно в 2 раза ускорить обучение на том же самом «железе». Одной из важных задач является разработка новых эффективных вычислительных методов обучения нейросетей, которые позволят снизить время обучения и потребление электроэнергии. Мы ведем над этим активную работу.
Ситуация с вычислительными мощностями она везде не очень хорошая, а не только в России. На рынке графических чипов, необходимых для обучения нейросетей, есть фактический монополист – компания NVIDIA, и все в мире осознают это, как глобальную проблему. NVIDIA ушла так далеко вперед, что сейчас проще купить у них процессор, чем пытаться разрабатывать свой.
Даже Google для своего последнего вычислительного кластера просто закупила у нее 26 тысяч графических карт, хотя у них есть свой специальный процессор для обучения нейросетей. Наличие такого монополиста не очень хорошо, но при этом надо понимать, сколько стоит разработка каких-то своих решений. Тут тоже есть варианты, что можно сделать, но это все средне- и долгосрочные перспективы. Пока же есть один путь – закупка графических карт и оптимизация алгоритмов. Нужно думать головой, а не просто механически увеличивать размер модели и объем железа необходимого для ее обучения.
Пример с ChatGPT показал простую вещь. Можно не обучать модель на сто миллиардов параметров, а создать и обучить модель в несколько миллиардов параметров. Это сокращение сложности и требуемых для обучения мощностей и электроэнергии в десятки раз. При этом можно получить сравнимое качество модели за счет более оптимальных алгоритмов обучения и грамотно подобранных данных.
Безусловные лидеры внедрения ИИ сейчас сервисы и сфера услуг. Почему ИИ-продукты так медленно внедряются в промышленность, сельское хозяйство? Там же очевиден огромный потенциал для ИИ.
В сельском хозяйстве действительно очень большой потенциал для ИИ-решений, связанных с обработкой спутниковых снимков, анализом различных рисков и предиктивной аналитики на основе этих данных. Просто есть высокая инерция, которая тормозит внедрение, плюс такой аспект, как стоимость труда. В тех агрокомплексах, где она невысокая, нет мотивации для оптимизации производственных процессов.
Имеется еще и «человеческий фактор». Специалисты в прикладных областях часто рассматривают датасайентистов как «персональных врагов», которые учат их тому, чем они занимаются много лет. не являясь специалистами в их области.
Если же говорить о промышленности, то ИИ можно использовать практически в любом технологически сложном производства, например, для контроля процесса сварки в режиме реального времени. Причем это все можно делать уже на готовых технологиях, не разрабатывая и не обучая нейросеть с нуля.
Среди претензий, которые предъявляют к разработчикам нейросетей, есть такая, что они не могут объяснить, как нейросеть пришла именно такому ответу, а не к другому. Это проблема?
Да, это большая проблема и для нее пока нет каких-то хороших решений, даже для обычных моделей, которые распознают лица с точностью до 99,999 %. Сейчас пытаются те же языковые модели, использовать для генерации объяснений, но какого-то вот разумного работающего подхода для повышения объяснимости работы моделей пока нет. Более того есть много примеров, когда можно злонамеренно модифицировать вход, модифицировать текст, модифицировать картинку и модель вообще начинает что-то другое предсказывать. Это одна из недавно открытых больших проблем. Но бизнес это не очень интересует, они говорят – вот у нас есть нейросеть с точностью работы 99,99 % и больше нам ничего не нужно. Человек и то чаще ошибается, а почему эта модель работает хорошо нам неважно. Сейчас в целом доминирует бизнес-подход, когда компании готовы внедрять ИИ для экономической выгоды. Либо, если они боятся и переживают, что цена ошибки будет слишком высока, они не внедряют ИИ, а просто используют его как помощника, как например в медицине.
А есть понимание барьера для развития ИИ если говорить о нейросетях?
Серьезного барьера пока не видно. Но, наверное, из тех задач, которые на данный момент считаются сложными, это те, где нужен не вероятностный, а один точный и правильный ответ и где нельзя выдавать правдоподобные версии. Усилия разработчиков фокусируются вот на таком классе задач.
Сейчас требуют изучения некоторые методики. Когда модели дают 100 задач, а потом просят ее придумать задачи, похожие на те, которые ее давали. Затем модель дообучается уже на тех задачах, которые она придумала себе сама и ее качество при этом существенно улучшается. То есть, фактически никаких новых данных не дается, а модель сама придумывает себе задачки, сама их решает и все это работает, но не очень понятно как. Это требует на самом деле системного объяснения.
В ближайшее время Правительство должно согласовать и утвердить федеральный проект «Искусственный интеллект». Как мы уже неоднократно отмечали в предыдущих материалах по теме , национального в этой доктрине – «ноль целых, ноль десятых», но адепты машинного управления людьми не могут остановиться. Теперь они твердо намерены закрепить использование алгоритмов ИИ для управления нашими «большими данными» в ГОСТах, причем осуществляется все это под прямой координацией из единого мирового центра. На основании свежих новостей «Катюша» продолжает вести летопись о последовательном уничтожении всего человеческого в социальной сфере и строительстве глобального электронного концлагеря.
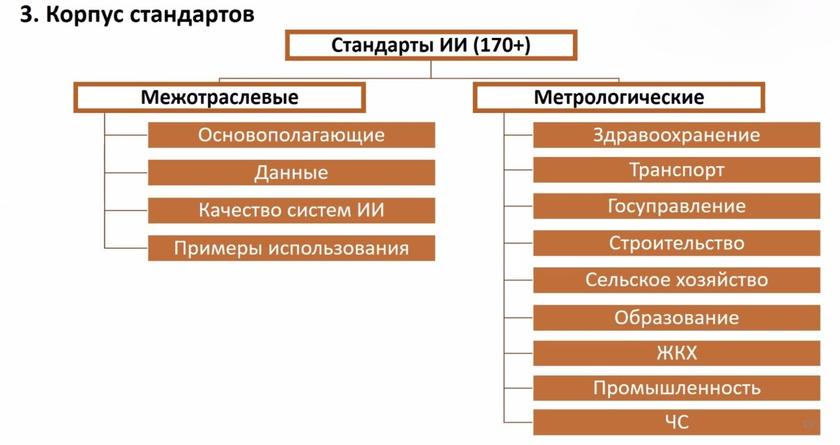
Мало кто из не погруженных в тему в курсе, что в России существует целый Технический комитет по стандартизации под названием «Искусственный интеллект» (ТК 164). Он был учрежден в 2019 году по инициативе Российской венчурной компании (РВК), а также при поддержке Минпромторга и Росстандарта. РВК – один из главных государственных инвесторов проектов трансгуманистов в России, причем в начале июня мы писали о задержании силовиками ее гендиректора Александра Повалко – руководство РВК подозревается в злоупотреблении полномочиями на миллионы долларов . В ТК 164 есть подкомитет под названием «Данные» (ПК 02), работу которого курирует центр компетенций «Национальной технологической инициативы» (еще одно АНО – порождение форсайтщиков, гендиректором «Платформы НТИ 20.35» является основатель Агентства стратегических инициатив и соавтор множества печально известных форсайт-проектов, главный «смотрящий» за оцифровкой РФ при президенте – Дмитрий Песков ).
30 июля 2020 года в режиме видеоконференции состоялось второе ежегодное заседание этого самого ТК 164, в котором приняли участие более 100 представителей компаний, научно-исследовательских организаций, вузов, органов власти, ассоциаций и фондов, входящих в комитет. Основная функция Технического комитета – составлять, апробировать и лоббировать утверждение Росстандартом ГОСТов для использования ИИ во всех сферах жизнедеятельности. Об этичности и возможных печальных последствиях передачи управления людьми бездушной машине, которую запрограммировали, в большинстве случаев, на Западе, поговорим позже. Уже во втором абзаце официального отчета видеоконференции мы встречаем весьма интересное пояснение:
«ТК 164 представляет собой зеркальное отражение на национальном уровне профильного международного подкомитета ISO/IEC JTC 1 SC 42 Artificial Intelligence».
Далее дадим слово председателю ТК 164, научному сотруднику Высшей школы экономики Сергею Гарбуку:
Второй (принцип) – максимальный охват тех отраслей, в которых нормативно-техническое регулирование искусственного интеллекта представляется наиболее важным и целесообразным, и создание соответствующих отраслевых подкомитетов. Это здравоохранение, транспорт, в будущем, возможно, безопасность»,
«Зеркальное отражение на национальном уровне» – звучит уж слишком мудрено. Объясним простыми словами – «наш» ТК 164 обязан внедрять и прививать на российскую почву все международные стандарты цифровизаторов из глобальной структуры под названием «Объединенный технический комитет № 1 ИСО/МЭК» (ISO/IEC JTC1). Это подразделение Международной организации по стандартизации (ISO) и Международной электротехнической комиссии (IEC). В структуре данного комитета действует подкомитет 42, отвечающий за ИИ. Именно он и спускает сверху своей российской ячейке в лице ТК 164 принятые международные стандарты, которые «наши» цифровизаторы должны преобразовать в российские ГОСТы. Очередное, уже сто первое доказательство, что конкуренцией, равно как и «невероятным рывком вперед», как и чем-либо инновационно национальным в процессе «цифровой трансформации» России никогда не пахло.
Будучи рядовой ячейкой ISO/IEC, ТК 164 полностью скопировал их структуру. Он также состоит из подкомитетов и рабочих групп, среди кураторов которых опять сплошь знакомые лица и прожекты: ПК 01 «Искусственный интеллект в здравоохранении» (на базе Научно-практического клинического центра диагностики и телемедицинских технологий Департамента здравоохранения города Москвы), ПК 02 «Данные» (на базе МГУ имени М.В. Ломоносова), ПК 03 «Искусственный интеллект на транспорте» (на базе компании «Яндекс»), РГ 01 «Основополагающие стандарты» (на базе Международного научно-исследовательского института проблем управления), РГ 03 «Качество систем искусственного интеллекта» (на базе Сколковского института науки и технологий), РГ 04 «Прикладные технологии искусственного интеллекта» (на базе ПАО «Сбербанк»), РГ 05 «Искусственный интеллект в образовании» (на базе НИУ «Высшая школа экономики»). Тут вам и обслуга глобалистов с космополитическим сознанием в лице МШУ «Сколково», и контора получившего практически неограниченную власть над российской социалкой и образованием безумного банкстера Германа Грефа (естественно, также представляющего интересы глобальных ростовщиков), и транснациональная компания «Яндекс», зарегистрированная в Голландии, председателем совета директоров которой является американский инвестор Джон Бойнтон.

Подкомитеты и рабочие группы ТК 164 серьезно заняты стандартизацией ИИ. За минувший год восемь документов доведены до конечной стадии разработки. Из них два утверждены и опубликованы в конце прошлого года (ГОСТ Р 58776-2019 «Средства мониторинга и прогнозирования намерения людей. Термины и определения»; ГОСТ Р 58777-2019 «Воздушный транспорт. Аэропорты. Технические средства досмотра. Методика определения показателей распознавания незаконных вложений по теневым рентгеновским изображениям»). Утвержденные стандарты напрямую касаются перевода страны на цифро-концлагерный режим, когда ИИ будет держать под постоянным учетом и контролем поступки и даже намерения людей (определение эмоций по биометрии лица, жестам и движениям людей и т.п.).
Три документа на данный момент прошли публичное обсуждение и находятся на стадии утверждения окончательной редакции в Росстандарте: 1.11.022-1.024.19 Информационная поддержка жизненного цикла изделий. Интерактивные электронные технические руководства с применением технологий ИИ и дополненной реальности. Общие требования; 1.11.022-1.021.19 Системы искусственного интеллекта. Классификация систем искусственного интеллекта; 1.11.022-1.022.19 Системы искусственного интеллекта. Способы обеспечения доверия. Общие положения. Еще по трем документам завершается стадия публичного обсуждения, либо разработчиками уже учитываются поступившие замечания: 1.11.164-1.025.20 Информационный технологии. Большие данные. Обзор и словарь; 1.11.164-1.012.20 Информационные технологии. ИИ. Ситуационная видеоаналитика. Термины и определения; 1.11.164-1.037.20 Средства мониторинга поведения и прогнозирования намерений людей. Аппаратно-программные средства для колесных транспортных средств. Классификация, назначение, состав и характеристики средств фото- и видеофиксации.
Г-н Гарбук не забыл пропиарить грядущие международные пленарные заседания международного комитета по стандартизации ИИ, с которым, само собой, у него налажено постоянное взаимодействие.

ТК 164 также находится в тесном партнерстве с ключевыми структурами глобалистов, которые пишут директивы для «наших» форсайтщиков, АНО при Правительстве и непосредственно для министерств и ведомств: ОЭСР, ЮНЕСКО, ООН, Еврокомиссией по ИИ.

Кто бы сомневался, что к приему везущих нам стеклянные бусы IT-колонизаторов нам, туземцам, надо будет подготовиться очень серьезно. Что касается общего корпуса стандартов для ИИ, его планируется довести до 170-200 документов. На финальном этапе утверждения машинное управление по прописанным глобалистами стандартам затронет абсолютно ВСЮ жизнь каждого из нас.
Исполнитель воли глобалистов Гарбук озвучивает задачи Технического комитета предельно откровенно: одна из ключевых целей стандартизации ИИ связана со снятием нормативных ограничений в области физической и информационной безопасности.
«Если говорить об информационной безопасности, это, прежде всего, тесная связь проблемы искусственного интеллекта с использованием больших объемов данных, которые зачастую являются конфиденциальными, содержат в себе персональные данные и так далее. Вопрос нахождения технологического и нормативного компромисса между соблюдением требований в области информационной безопасности и между снятием препятствий для недискриминационного доступа разработчиков к этим большим данным – этот вопрос не решен ни у нас в стране, ни в мире, его предстоит решить», – заявил Гарбук.
Естественно, этот господин умеет мыслить исключительно глобально – не только за нашу страну, но и за весь мир. Перед ним поставлена крайне важная для форсайтщиков задача – снять все законодательные препятствия для обработки персональных данных населения, а также дать доступ «искусственному интеллекту» непосредственно к телам, сознанию и эмоциям людей – в медицине, образовании, сфере безопасности и т.д. Как вообще можно рассуждать о каком-то «недискриминационном доступе разработчиков» к нашим конфиденциальным и персональным данным, если их обработка без согласия гражданина запрещена Конституцией РФ даже в случае введения в стране чрезвычайного положения? Очевидно, конституционные права граждан для цифросектантов – как бельмо в глазу.
Отдельного внимания в рамках мероприятия ТК 164 заслуживает презентация рабочей группы 05 «Технологии искусственного интеллекта в образовании» при ТК 164 (полная версия доступна по ссылке ). В настоящее время она ведет работу над следующими ГОСТами:

Как видим, здесь полный набор для стандартизации (фактического узаконения) всех «инноваций», озвученных форсайтщиками Лукшей и Песковых еще семь лет назад, в подробно разобранном «Катюше» докладе «Образование будущего: глобальная повестка», ставшим фундаментом для «Образования-2030» и «-2035» ). Тут вам и персональные траектории развития, которые для обучающегося человека будет подбирать машина исходя из обработанных ей персональных данных и вложенных в нее алгоритмов, и возможность собирать, обрабатывать, хранить и передавать бесценные личные данные наших детей (их защита – этот пункт включен просто для перестраховки глобалистов, он волнует их в последнюю очередь), и эксперимент по испытанию искусственного интеллекта в общем образовании – то есть в качестве подопытных в этом «адаптивном обучении» будут наши с вами дети. Это настоящее узаконенное рабство для «человеческого капитала» под руководством ИИ (точнее, его программистов и регуляторов, считающих себя «избранной элитой»).
Не менее интересен отчет подкомитета 01 «Искусственный интеллект в здравоохранении», согласно которому вскоре нас ждет утверждение общих ГОСТов, внедряющих системы ИИ в клиническую медицину . Причем в одном из пунктов предлагается сосредоточиться на «выявлении и предотвращении рисков, создающих угрозу жизни и здоровью граждан, и минимизации последствий их наступления». То есть прямо признается, что риски для жизни и здоровья людей, которых будет «лечить» и «диагностировать» ИИ, очень большие. Главным лоббистом новых стандартов выступает ГБУЗ «Научно-практический клинический центр диагностики и телемедицинских технологий Департамента здравоохранения города Москвы» во главе с д.м.н. Сергеем Морозовым. Что характерно, первыми подопытными гражданами, личные данные о здоровье которых (составляющие медицинскую тайну!) были скормлены ИИ, стали заболевшие коронавирусной пневмонией. Перед тем как сделать КТ, отчаявшиеся люди подписывали согласие на обработку ПД, после чего их рентгеновские снимки свободно использовались для «обучения» нейросетей способности видеть картину «матового стекла» и т.д. КОВИД-19 стал отличным подспорьем для цифросектантов.
Естественно, Технический комитет по стандартизации ИИ не является первопроходцем на этой ниве. Нейросети, большие данные, сбор сведений с населения, попытки подчинить человека холодному цифровому алгоритму– все это последовательно и не один год насаждается командно-административными методами при руководящем участии некоммерческих структур при Правительстве (хорошо нам известных АНО АСИ, АНО «Цифровая экономика», Фонд «Сколково», НТИ), а также Российской венчурной компании и ныне уже правительственного Сбербанка.
«Именно на системе образования лежит ответственность за адаптацию человека к новой реальности. Образование формирует мышление и ключевые компетенции. Поэтому от него зависит, насколько человек будет успешен в новой среде обитания. Чтобы эффективно решать эту задачу, образование должно измениться: отвечать запросам, представлениям и протоколам коммуникации цифрового человека.
Как вы готовы измениться внутренне, чтобы соответствовать условиям и требованиям цифровой эпохи и задаче технологического прорыва?
Мы считаем, что перед всеми субъектами системы образования цифровая трансформация ставит 4 ключевых вызова-перехода:
1. к управлению на основе данных; 2. к актуальному и постоянно обновляемому содержанию образовательных программ; 3. к представлению о человеке как обитателе цифровой среды (что порождает новые требования и к нему, и к системе образования); 4. к представлению об университете как части цифровой экосистемы образования».
Итак, от участников интенсива напрямую требуется «измениться внутренне, чтобы стать цифровыми людьми» (!), которые затем будут управляться (направляться в течение всей своей жизни!) ИИ на основании регулярно собираемого и обновляемого им персонального цифрового следа. Обратите внимание, какие сведения они хотят собирать о каждом из нас, именно эти данные в качестве эксперимента обрабатывались у участников «Острова»: о перемещениях человека, активности его мозга, эффективности его энергообмена, физической форме, когнитивных способностях и отдельных параметрах генома (!).
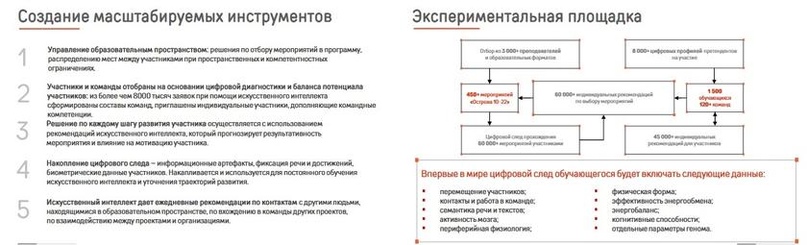
Форсайтщики из НТИ предлагают вступить в добровольный эксперимент по тотальному контролю и управлению людьми искусственным интеллектом.
После анализа собранной ИИ информации руководство вузов будет решать: поощрить учащегося, посоветовать пройти дополнительные курсы, активнее спрашивать его на парах, предупредить о ненадлежащем поведении или отчислить. Такая система якобы позволит исключить предвзятость со стороны преподавателей. Для тестирования системы выберут несколько вузов, ее внедрение начнется уже в этом году, а к 2021-му в отдельных университетах будут действовать опытные образцы, сообщил директор Центра EDCrunch University (международный проект и одноименный форум по уничтожению традиционного образования) МИСиС Нурлан Киясов.
В выступлении Дырмовского был упомянут разработанный в марте этого года и находящийся на согласовании в Правительстве федеральный проект «Искусственный интеллект». Скорее всего, именно он будет определять «дорожную карту» реализации технологий ИИ в рамках нацпроекта «Цифровая экономика». Его хотят принять в экстренном порядке до начала запланированной «уважаемыми партнерами» на осень второй волны пандемии КОВИД-19, получив таким образом возможности для ничем не ограниченных опытов над русским народом в рамках непрекращающегося режима «повышенной готовности».
Карт-бланш на любые эксперименты с внедрением ИИ во все сферы жизни общества «партия коронавируса» (она же – команда слуг форсайтщиков-глобалистов во власти РФ) фактически уже получила: благодаря принятию антиконституционного закона об экспериментальных правовых режимах, в рамках которых цифросектанты по всей стране могут плевать на действующие законы и гарантированные ими права и свободы граждан . Сбывается голубая мечта многозадачного безумного банкстера-трансгуманиста Германа Грефа, лично просившего президента России дать ему неограниченные права на издевательства над школьниками и студентами , в том числе на внедрение тех же персональных образовательных траекторий и ИИ в образовании. А целый корпус разрабатываемых новых ГОСТов закрепит нормативно-техническую базу для экспериментов. Причем технические стандарты, в отличие от обсуждаемых в Госдуме законопроектов, свободны от четкого соблюдения прав и свобод граждан – достаточно вспомнить про действующий ГОСТ Р 43.0.3-2009 («Информационное обеспечение техники и операторской деятельности. Ноон-технология в технической деятельности. Общие положения»), где легализуется вот такой занимательный процесс:
«3.57 цефализация деятельности мозга: Изменение мышления, мыслительной деятельности мозга оператора применением информационных воздействий на физиологическую структурно-организменную деятельность мозга для управления (!!!) его информационно-интеллектуальной деятельностью».
В этом бушующем океане цифробесия нам недвусмысленно намекают, что об общепринятых нормах биоэтики, морали, как и о сложившихся представлениях о человечности, гуманизме, в создаваемой цифровой среде для биообъектов (т.е. нас с вами), совсем скоро никто и не вспомнит. Цифросектанты просто вывели нас за скобки, забыв спросить, мечтаем ли мы стать подопытными марионетками администрируемых глобалистами нейросетей, хотим ли отдавать определение своей судьбы на откуп бездушным железкам с микропроцессорами? Но мы верим, что народ России очень даже способен дать однозначный ответ строителям планетарного электронного концлагеря – не дожидаясь их вопросов.
Читайте наш сайт!!!
Поддержать наш проект пожертвованием
Всего не перечесть
Перспективы использования ИИ в госуправлении большие, Минцифры перечисляет лишь некоторые примеры, полагает управляющий директор практики «Данные и прикладной ИИ» Axenix (экс-Accenture) Лариса Малькова. «Областей и сценариев применения намного больше — так, вся концепция «умного города» базируется на технологиях ИИ и больших данных как ключевых, от медицины до безопасности, включая даже мониторинг безнадзорных собак и незаконных торговых объектов», — говорит она.
Важным аспектом является прозрачность систем ИИ, указывают эксперты. На этапе их внедрения важно проинформировать общество о том, как они работают, какие данные используются для обучения и какие данные система собирает в процессе работы, обращает внимание руководитель NLP R&D команды в Just AI Константин Котик. Не случайно, говорит он, в своих последних обращениях глава Open AI Сэм Альтман призывает все страны разрабатывать меры регулирования ИИ, прежде чем внедрять их в государственные системы. «Также стоит вопрос о безопасности моделей ИИ. Так как они обрабатывают большое количество данных, часть из которых является личными, пользователи должны быть уверены в том, что их данные надежно защищены и зашифрованы», — рассуждает Котик.
В каких-то государственных системах уже активно используются алгоритмы ИИ: например, в московском метро ИИ распознает лица людей, находящихся в розыске, сверяя данные с фотобазой, в Лос-Анджелесе на базе ИИ работает система предсказания преступности. «При грамотном внедрении и обучении систем ИИ они могут стать полезными инструментами, работающими на благо общества», — продолжает Котик.
Сегодня решения на основе ИИ зарекомендовали себя во многих отраслях экономики — от ретейла до финансовой сферы. «Вполне логично, что государство тоже хочет использовать передовые разработки на основе ИИ и совершенствовать за счет них свои сервисы. Российские вендоры готовы в этом помогать», — размышляет генеральный директор Content AI Светлана Дергачева. ИИ можно и нужно использовать в медицине, строительстве, но в самой ближайшей перспективе нашей стране нужно решить главную проблему — доступ к технологиям и серверным мощностям, без которых невозможен рывок, считает партнер и директор по развитию HRlink Дмитрий Махлин.
Что касается предложения Минэкономразвития обязать компании при получении господдержки внедрять ИИ, то, с одной стороны, оно стимулирует развитие ИИ, а с другой — может привести к тому, что компании будут внедрять ИИ ради ИИ без понимания его потенциала и ограничений, полагают участники рынка.
«ИИ требует значительных инвестиций в разработку и поддержку, и без четкого плана использования и ожидаемого результата итогом могут стать ненужные затраты и потеря доверия к технологии. Внедрение систем ИИ должно быть направлено на решение конкретных бизнес-задач», — убежден Константин Котик.
Чтобы инициатива Минэка стала драйвером развития таких технологий в России, нужно систематизировать диалог о цифровизации между заказчиками и разработчиками — тогда вендоры смогут оперативно подбирать и адаптировать продукты под нужды конкретных бизнесов, говорит Дергачева.
Пройтись по списку
На совещании президента с членами правительства во вторник, 18 июля, глава Минцифры Максут Шадаев обозначил приоритетные направления для внедрения технологий ИИ в системе госуправления. Первым из них, согласно сообщению Минцифры, идут «простые и понятные госуслуги» (пользователь не должен разбираться в бюрократических нюансах, идеальный вариант — он задает вопросы и получает конкретные ответы). Так, Минцифры сейчас реализует пилотный проект с голосовыми помощниками «Яндекса» и «Сбера», чтобы можно было задавать вопросы голосом и получать такой же голосовой ответ. «Планируем запустить проект до конца года», — заявил Шадаев.
Далее ИИ может помогать планировать территориальное развитие. Минцифры разрабатывает рекомендательную систему, которая будет подсказывать оптимальные места для строительства новых школ, детсадов, поликлиник с учетом транспортной доступности, плотности застройки, обеспеченности социальной инфраструктурой, утверждают в ведомстве.
Кроме того, ИИ может упростить медицинскую диагностику. «Это возможность в автоматическом режиме находить признаки заболеваний на электронных медицинских изображениях, — поясняют в Минцифры. — Алгоритмы успешно обучаются на медицинских обезличенных снимках с уже выявленными заболеваниями и дальше могут подсказывать врачу, на что именно обратить внимание».
Еще два направления относятся к анализу спутниковых снимков и алгоритмам в наблюдении за погодой. В первом случае ИИ способен определять места незаконной вырубки леса, анализировать эффективность использования сельхозземель, выявлять незарегистрированные объекты недвижимости для постановки на учет и т. д. Во втором большой датасет, за многие десятилетия сформированный в Росгидромете, «позволит тестировать новые технологии прогноза погоды, они будут более качественные и точные».
Минцифры также предлагает возложить задачи по управлению большими данными и внедрению технологий ИИ на руководителей цифровой трансформации как в федеральных ведомствах, так и в регионах, и включить показатели по внедрению ИИ в стратегии цифровой трансформации госкомпаний. Кроме того, министр экономического развития Максим Решетников в ходе совещания заявил, что Минэкономразвития предложило сделать обязательным условием приобретение и использование решений с ИИ при получении бизнесом субсидий выше определенной суммы.